Why does GRPO work?
DeepSeek.
Everyone in the LLM space knows that name now, and for good reason; after a little over a year of their team quietly iterating on architecture, engineering, & data work, they've finally caught up to [and in some aspects surpassed] the frontier with the release of DeepSeek r1, fresh off the heels of their latest pretraining run (DeepSeek-V3).
When OpenAI released the first checkpoint that they felt confident enough in to dub a "reasoning model" (o1-preview), speculation went wild trying to figure out what training advancement was responsible for the performance lift that was being observed. Nobody in academia truly reproduced something at this level out in the open for several months. Not until r1 arrived.
So how did they do it?
Some individuals speculated that the advancement here came from integration of algorithms that have seen success in other contexts when it comes to ML, such as Monte Carlo tree search, or schemes that involved process reward modeling where each step is individually rewarded.
It turns out all those galaxy brain schemes were beaten out by a clear answer;
literally any reasonable variant of online reinforcement learning applied to verifiable objectives.
While frontier labs at large are [presumably] still using PPO for online RL, DeepSeek developed what can be argued as strictly inferior from a pure learning perspective; but the reason why this doesn't matter is that the core principle of optimization essentially remains the same between the two methods.
It turns out that custom RL objectives which explicitly reward the criteria that you are looking for are vastly more important for strong grounding in the task compared to just doing a finetune over the data you have and hoping for the best. But some elements of the PPO algorithm are more important than the others for the objectives we're aiming to optimize for.
The crux of what actually matters that distinguishes PPO and GRPO is that:
GRPO avoids the complexity associated with having a value model estimate the "usefulness" (advantage) of a sample [when it comes to optimizing for a goal] by weighing the samples according to how much they contribute to the reward.
I won't get too much into the woods when it comes to the math here because that shit bores me to death, but the important thing about this setup is that since you are already taking multiple generations per training sample in a online RL setup, you can use the natural variability of these samples to estimate your advantage simply by comparing them to each other.
That is to say, if generation 1 has a reward of 0.5, and generations 2, 3, and 4 are 0.1, you want to favor the probability of producing generation 1 more than the others, and by doing this in an relative fashion iteratively, you can naturally hill climb your desired metric by always favoring the samples that are proximally closer to improving your desired reward.
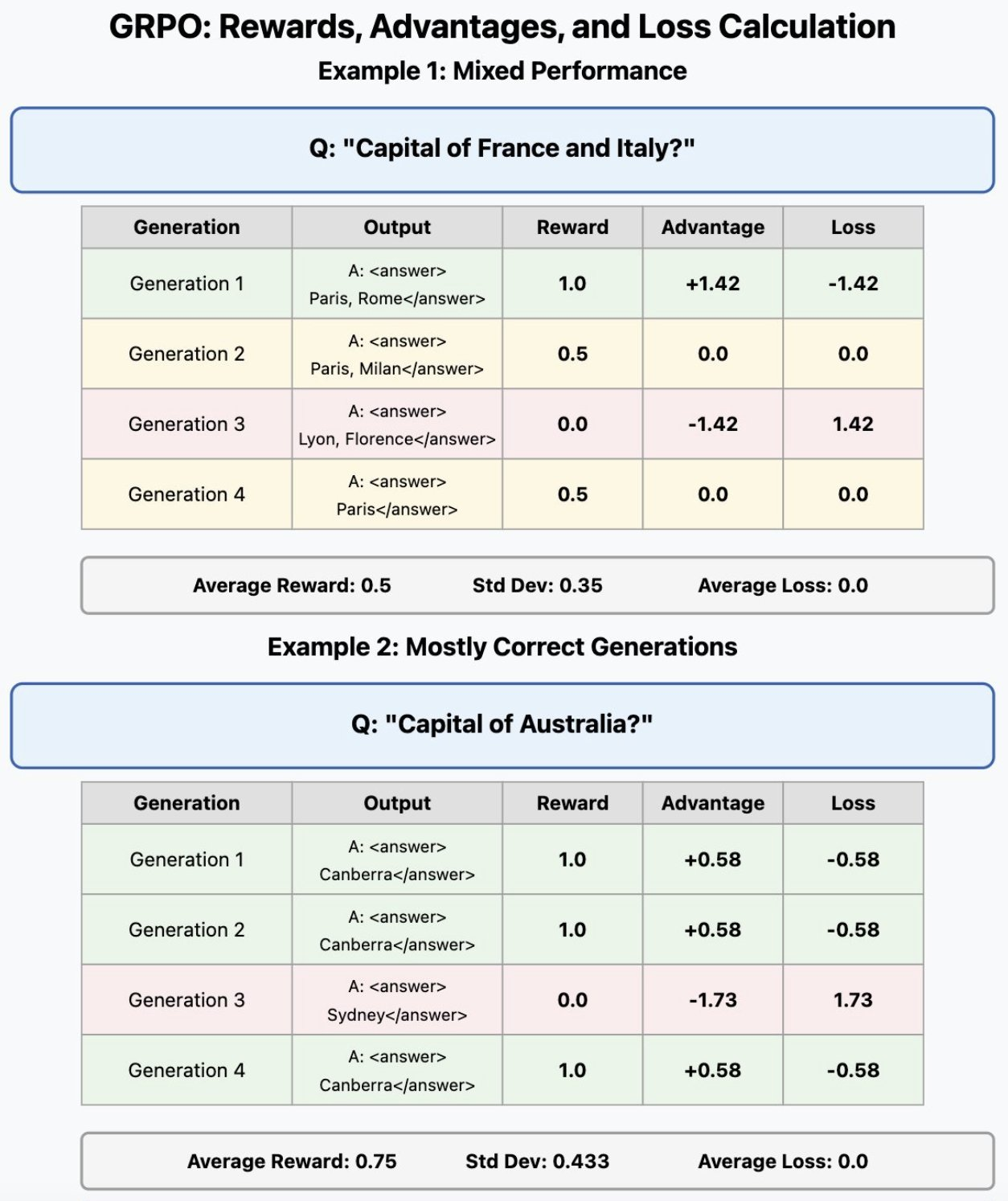 What's most critical to observe here is how the advantage is calculated relative to performance of other attempts in the group.
What's most critical to observe here is how the advantage is calculated relative to performance of other attempts in the group.
The advantage for each of the generations is calculated as such:
advantage = (reward - mean) / stddev
DPO Delenda Est, or: The Bitterer Lesson
For a year or so before r1's release, open source was infatuated with the idea of "DPO" (Direct Preference Optimization), which eschews the "online" nature of reinforcement learning entirely by attempting to maximize the distance between "chosen" and "rejected" data given a pre-existing dataset.
That is to say, instead of generating responses and iteratively improving them, DPO trains on an offline dataset and maximizes the probabilistic distance between chosen and rejected response pairs.
I am of the opinion that this seems to have held back some pretty trivial experimentation that could have been done in the open source space to make online RL cheaper in the same ways that DeepSeek has demonstrated with GRPO as an algorithm, and to be blunt, I don't believe that DPO as an idea was ever going to work out in the long term.
So, why doesn't DPO "work" (for the kinds of problems that GRPO is good at handling)? Well, if you think about it, it's essentially a proxy objective for another proxy objective; that being, preference reward models, which are classifiers trained to predict the chance that a response is "preferred" compared to the chance that it is "dispreferred" (Bradley-Terry model).
We cannot directly "train" on "true" human preferences, because what people like more or what is considered subjectively better on average is not typically contingent on verifiable or measurable factors; so we use the reward model as a proxy of determining what would be liked more based off of human annotated preference data.
When you remove a model of preferences from the equation, you are essentially just maximizing the difference between what is already likely to happen vs what is less likely to happen; and as such, methods like DPO can never generalize from a base model, and will never learn the "true distribution" of what is preferred. As such, DPO is considered an "offline" version of RL; instead of learning to produce iteratively better outcomes "on the fly", the model gets prescribed pre-packaged predictions that might not even naturally align with the profile of what the model is predisposed towards producing to begin with.
In fact, it can lead to performance degradation and catastrophic forgetting when the chosen/rejected data being used is simply too far away from what the model actually produces.
To make matters worse, what the model "puts out" will always be shifting across the course of training, so even pre-collecting your chosen and rejected data according to a preference model or classifier will lead to "stale" representations of what the trained model would actually produce compared to if you trained the model in an online fashion.
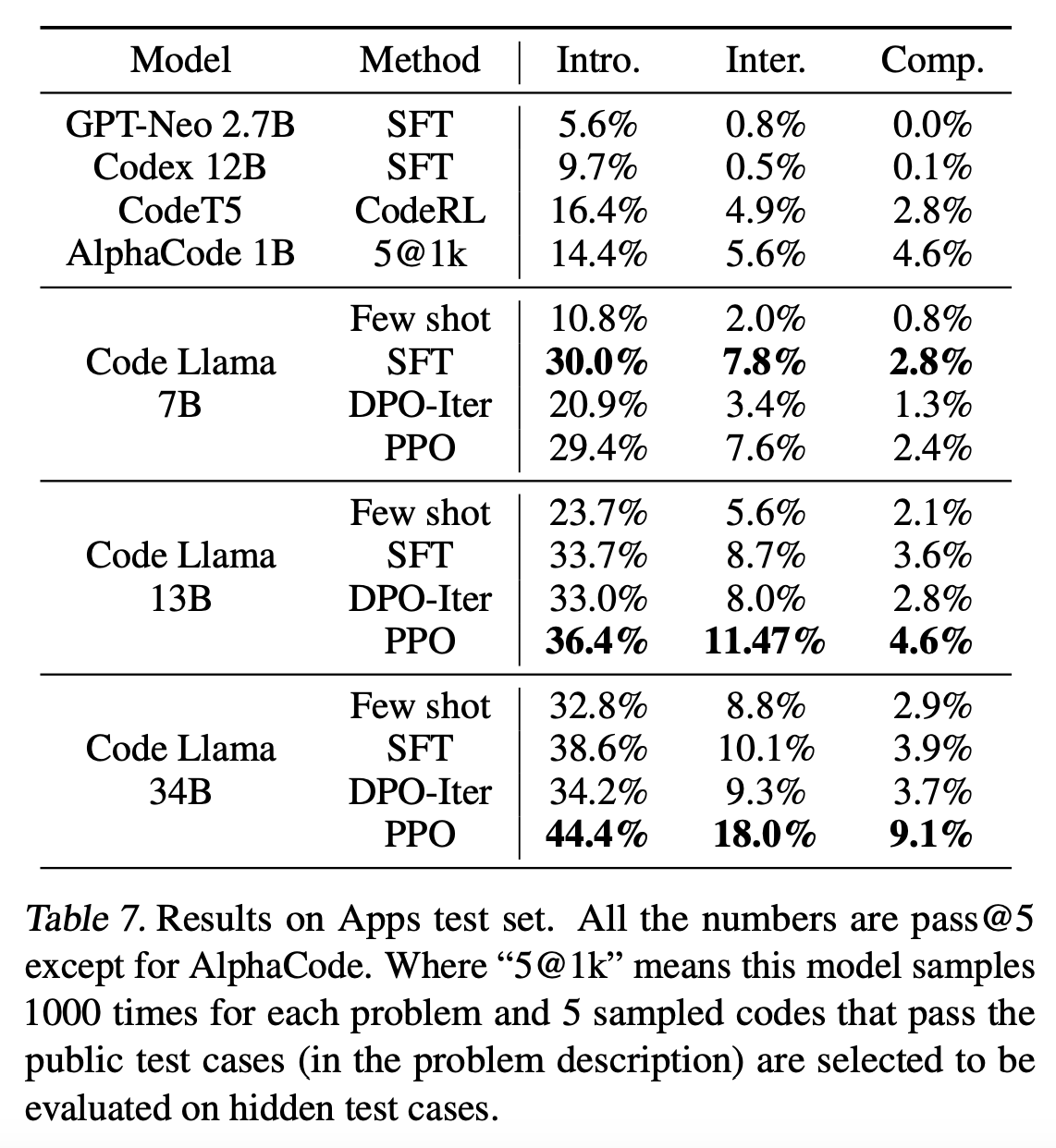 womp womp! (for a more rigorous analysis of DPO vs online RL methods like PPO, see Duan et al. (2024))
womp womp! (for a more rigorous analysis of DPO vs online RL methods like PPO, see Duan et al. (2024))
The (Design) Philosophical Difference
Another (non-technical) problem this caused was an implicit assumption that optimizing for preference is more important than optimizing for outcome-based objectives; that it's the only approach that matters. In reality, I would argue that the utility of RL for language models has been pigeonholed not by technological limitations but by aspirational ones.
The most useful thing about online RL, the thing about it that makes it so unbelievably powerful when correctly applied to these models at scale, is that you do not have to operate in the space of "optimizing for more accurate token predictions".
Why?
Well.
When it comes to whatever metric you have chosen for your reward in online RL.
- If you can accurately measure it,
- and the model is already capable of accomplishing it to some degree,
- at least some of the time...
...then you essentially have a "soft guarantee" of sorts, that you'll be able to iteratively optimize in the direction of maximizing it.
Of course, you're bound to the intrinsic limits of that metric (see the existence of reward gaming), but if you have a metric that is guaranteed to always be correct, such as mathematical accuracy...
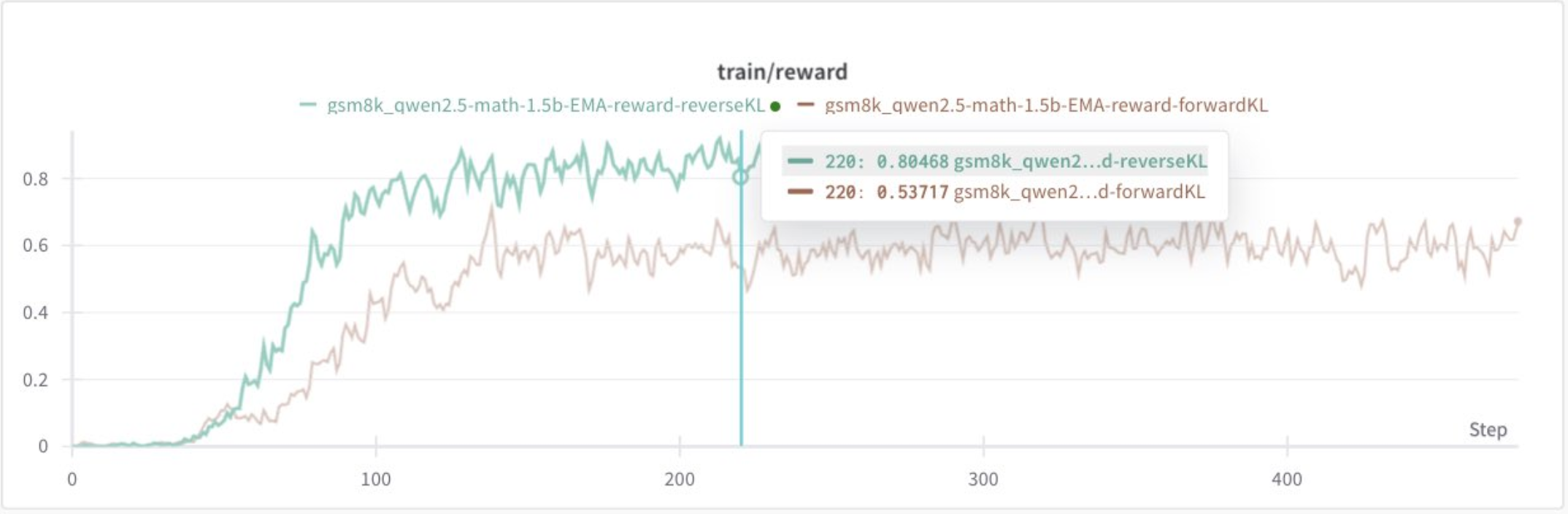 from (almost) zero to hero!
from (almost) zero to hero!
Then you now have a direct path towards meaningful improvement.
This is the fundamental thing about policy gradients that makes them capable of turning a model that nearly never gets something right into a model that can one-shot complex problems reliably. In RL, you're not learning from data directly so much as you are learning from the continued direction of improvement in achieving what the reward metric implies.
This essentially gives you the ability to model the process of learning, instead of just observing the outcomes achieved by those who've already learned (which I am analogizing SFT-based finetuning as being equivalent to here).
What GRPO and r1 should teach people more broadly is that, while modeling the process of learning to achieve a goal may be difficult, if you do it correctly, it'll always get you more reliable and generalizable results compared to just imitating a known outcome.
It just so happens that pretraining on trillions of tokens of human articulation via "outcome approximation" is the fastest way towards imbuing intelligent prior understanding into these models. But in order to get them to achieve abstract goals like "reliably producing working Python code", you need to define metrics that (when optimized for) necessarily imply those kinds of outcomes.
You're never going to get that exclusively from plain reduction of cross-entropy over text.
But you can sure as hell get the starting point for it from that.